
Explainability-Guided Synthetic Data Curation
Making good synthetic data, shaped by model insights
Dear SoTA,
For many machine learning problems, data scarcity and class imbalance are major bottlenecks that act to limit model performance. Synthetic data has emerged as a powerful tool to supplement real-world datasets, and can be generated using methods ranging from GANs and variational autoencoders, to simulators and game engines.
But a persistent ambiguity remains: should synthetic data aim for photorealism [1], reinforcing real-world distributions, or embrace domain randomisation [2], where parameters such as lighting, textures, and backgrounds are deliberately varied to push models toward more robust generalisation? Both strategies have shown success in different settings, yet it is often unclear which aspects of synthetic imagery actually drive improvements.
This is the question our work addresses: what makes good synthetic data?
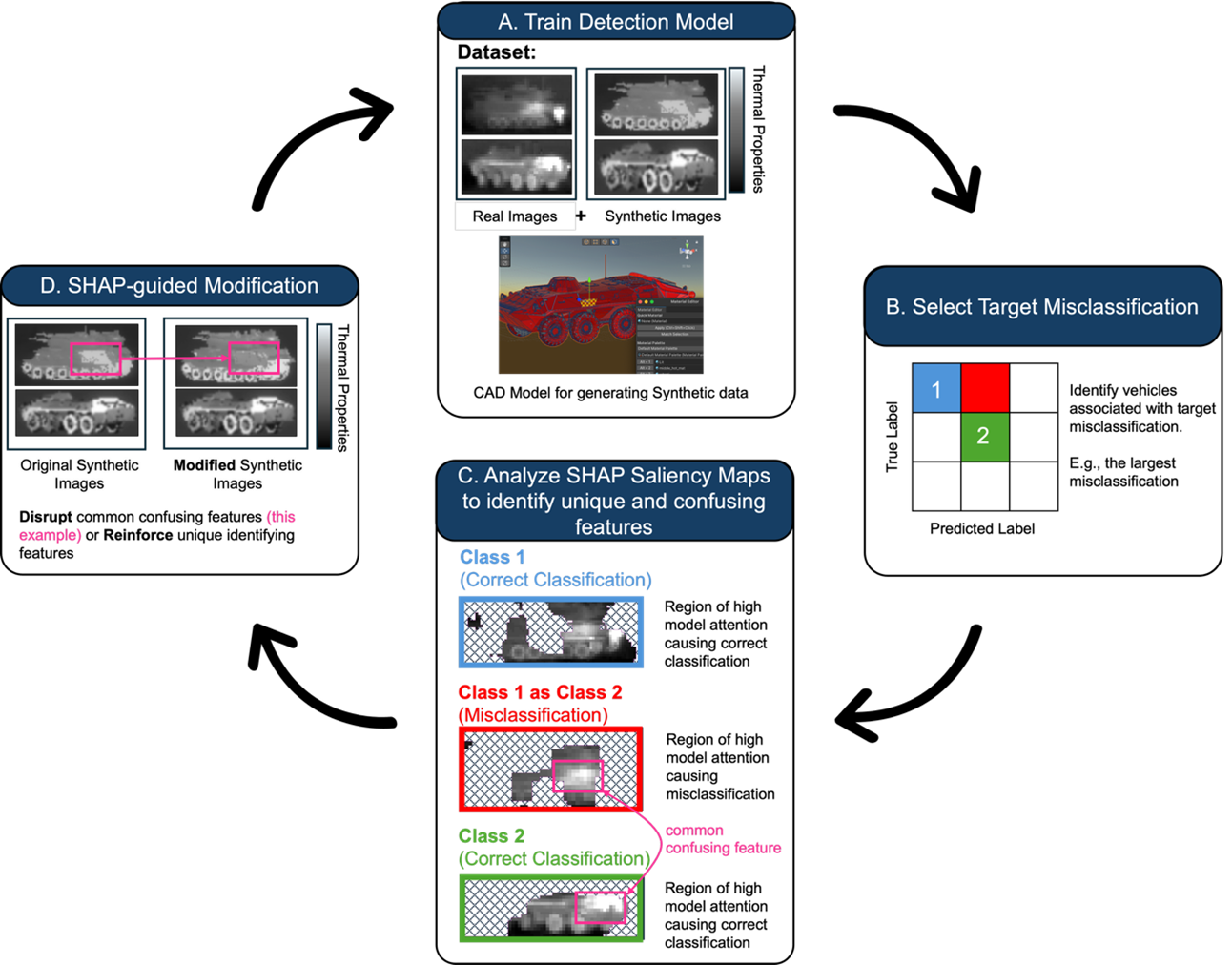
Model pipeline for refinement of synthetic data from gaming engine CAD models. Refining synthetic data through CAD model changes for a target misclassification using SHAP saliency maps to identify unique class features and common inter-class features associated with misclassification.
SHAP-guided synthetic data refinement
Our study [3] offers a novel approach: using explainable AI (XAI) to refine synthetic data generation. Using an object-detection model trained on an infrared vehicle dataset and synthetic data generated from 3D CAD models, we applied a game theory derived explainability method called SHAP (SHapley Additive exPlanations) to figure out exactly which parts of an image influence the model’s decisions. We derive global explanations by aggregating the local SHAP values computed for individual samples over representative subsets of the data for correct classifications and misclassifications. By comparing SHAP “saliency maps” across correct classifications and frequent misclassifications, we could see which visual features were genuinely useful and which were leading the model astray.
Armed with these insights, we introduced two types of targeted adjustments:
· Reinforcing modifications: emphasizing the unique features that help tell objects apart (e.g. tweaking textures to highlight the body shape of a particular vehicle).
· Disruptive modifications: toning down misleading features that caused confusion (e.g. muting thermal hotspots that made two vehicles look alike in infrared).
The results were impressive. On a challenging task—detecting and classifying vehicles in infrared images - the baseline model trained only on real data achieved 90% accuracy (mAP50). Adding unmodified synthetic data bumped this up to 94.6%. But with SHAP-guided refinements, accuracy climbed further to 96.1%, cutting key misclassifications in half. Even more striking, this improvement outperforms established techniques for optimising detection performance such as varifocal loss and online hard-example mining, focusing on hard examples during training in order to improve generalisation; this shows that smarter data curation can sometimes matter more than clever tweaks to training algorithms.
Why does this matter? Because many AI applications—from self-driving cars to medical diagnosis—suffer from the same problem: rare or under-represented cases that models struggle to handle. SHAP-guided refinement offers a way to systematically generate synthetic examples that target those blind spots, helping models learn from the right cues instead of the wrong ones. Perhaps most excitingly, this approach flips the usual story of explainability. Instead of just using XAI to interpret a trained model, here explanations actively shape the training process itself.
Limitations
This approach is powerful, but not without challenges. SHAP saliency maps highlight where a model is focusing, yet it does not reveal what feature it is attending to—whether that’s shape, texture, brightness, or something else. Human operators must still interpret these maps and decide how to adjust the synthetic meshes. The process also relies on manual editing of 3D models and involves a fair amount of trial and error, since small changes can trigger unpredictable ripple effects in other vehicle classes. In its current form, the method remains partly artisanal and heavily dependent on expert judgment.
Our ongoing work aims to automate much of this loop. First, mechanistic interpretability can complement SHAP analysis by pinpointing what features need to be modified, for example by using sparse autoencoders to isolate small sets of neurons whose activations consistently track the unique or misleading features that we act on with reinforcing or disruptive modifications. And second, a large language reasoning model can combine the explainability and interpretability insights, propose candidate modifications and instruct the corresponding CAD model changes. and then retrain the model. Together, these steps would make the process faster, more scalable, and less reliant on manual effort.
Multimodal Automated Interpretability Agent (MAIA)
This final “orchestration step” is perhaps the most challenging to automate, requiring iterative cycles of reasoning and targeted synthetic modifications. We explored this idea in a proof-of-concept during SoTA’s Opening the Black Box interpretability hackathon, where we won the grand prize in January 2025. Our prototype built on the multimodal interpretability agent (MAIA) [4], which we enhanced with a sparse autoencoder to enforce mono-semantic neuron representations. In MAIA, given a neuron, the framework identifies its highest-activation images in a pretrained model, then prompts an LLM to hypothesize what that neuron represents. The agent iteratively tests and refines this hypothesis by generating new examples with diffusion models until it converges on a consistent interpretation.
However, whilst MAIA asks, “what feature does a neuron represent?”, we’re interested in the inverse of this problem. Our challenge instead starts with features highlighted by SHAP and asks, “which neurons encode this feature?”. Solving this mapping is critical to automating synthetic data refinement, but MAIA also suffers from a second limitation: its reliance on diffusion-generated images, which can hallucinate details and lack grounding in physical realism.
Automatic mesh modifications in the game engine
To overcome the second problem, we shift the focus from image editing to direct mesh modification in a simulator. Instead of diffusion-based edits, we use Unity gaming engine as a controlled environment, where 3D meshes can be modified whilst keeping physical and semantic constraints intact. Building on an agentic workflow, we connect an LLM to Unity through a Model Context Protocol (MCP) server, using the ReAct reasoning framework to propose, implement, and evaluate mesh-level changes. This allows us to scale refinement to large synthetic datasets while preserving realism, bridging the gap between interpretability insights and practical dataset modification.
Conclusion
Together, SHAP-guided refinement and our ongoing work toward automation provide a framework where synthetic data isn’t just generated, but intelligently shaped by model insights. By closing the loop between explainability, simulation, and data design, we can build training sets that directly address model blind spots. This shift - from passive data generation to active, model-guided curation - has the potential to make machine learning systems more accurate, robust, and trustworthy across domains.
Best,
Nitish Mital and Simon Malzard
[1] Bordes, Florian, et al. “Pug: Photorealistic and semantically controllable synthetic data for representation learning.” Advances in Neural Information Processing Systems 36 (2023): 45020-45054.
[2] Tremblay, Jonathan, et al. “Training deep networks with synthetic data: Bridging the reality gap by domain randomization.” Proceedings of the IEEE conference on computer vision and pattern recognition workshops. 2018.
[3] Mital, Nitish, et al. “Improving Object Detection by Modifying Synthetic Data with Explainable AI.” arXiv preprint arXiv:2412.01477 (2024).
[4] Shaham, Tamar Rott, et al. “A multimodal automated interpretability agent.” Forty-first International Conference on Machine Learning. 2024.